Re-muestreo
Train-Test-Cross
Métodos de re-muestreo
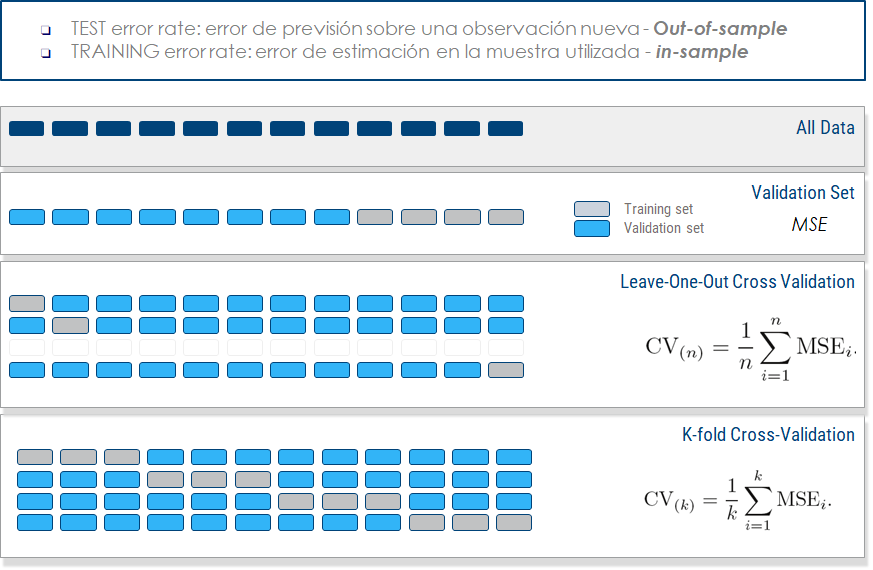
Figure 1: Métodos de Remuestreo
Training & testing
Lo primero que debemos hacer para conseguir una buena evaluación es dividir los datos en dos subconjuntos. Uno para entrenar el modelo (training) y otro para evaluar el modelo (testing). El partición entre estos dos subconjuntos suele hacerse de forma aleatoria, aunque según el problema podemos usar otros criterios. Por ejemplo, si los datos que tenemos son una serie temporal, entonces podemos dividirlos a partir de un cierto tiempo. Es decir, coger como test los datos más recientes.
La razón de hacer esta división es usar los datos del subconjunto training para entrenar el modelo y luego evaluar los datos del testing. De esta manera simulamos correctamente una evaluación, ya que no podemos evaluar unos datos si hemos entrenado con ellos. Por lo tanto, los datos de testing no deben ser observados por el algoritmo.
Cross validation
El procedimiento que se suele usar para evaluar un modelo es cross validation o validación cruzada. La idea básica de cross validation consiste en dividir los datos en \(k\) subconjuntos. Cada subconjunto se predice mediante un modelo entrenado con el resto. De esta manera podemos hacer una evaluación sobre todos los datos y evitamos el problema de obtener una muestra sesgada si sólo lo hiciéramos una vez.
Romy Rodriguez-Ravines
GOING BEYOND DATA
Understand, Model, Predict = Learn and extract value from data for people and organizations.